Regresión Lineal
Para otros usos de este término, véase Función lineal (desambiguación).

En estadística la regresión lineal o ajuste lineal es un método matemático que modela la relación entre unavariable dependiente Y, las variables independientes Xi y un término aleatorio ε. Este modelo puede ser expresado como:

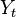 : variable dependiente, explicada o regresando.
: variable dependiente, explicada o regresando. : variables explicativas, independientes o regresores.
: variables explicativas, independientes o regresores.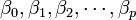 : parámetros, miden la influencia que las variables explicativas tienen sobre el regresando.
: parámetros, miden la influencia que las variables explicativas tienen sobre el regresando.
donde  es la intersección o término "constante", las
es la intersección o término "constante", las  son los parámetros respectivos a cada variable independiente, y
son los parámetros respectivos a cada variable independiente, y  es el número de parámetros independientes a tener en cuenta en la regresión. La regresión lineal puede ser contrastada con la regresión no lineal.
es el número de parámetros independientes a tener en cuenta en la regresión. La regresión lineal puede ser contrastada con la regresión no lineal.
es la intersección o término "constante", las son los parámetros respectivos a cada variable independiente, y es el número de parámetros independientes a tener en cuenta en la regresión. La regresión lineal puede ser contrastada con la regresión no lineal.Índice[ocultar]
|
[editar]
Historia
La primera forma de regresiones lineales documentada fue el método de los mínimos cuadrados, el cual fue publicado por Legendre en 1805,1 y en dónde se incluía una versión delteorema de Gauss-Márkov.
[editar]
Etimología
El término regresión se utilizó por primera vez en el estudio de variables antropométricas: al comparar la estatura de padres e hijos, resultó que los hijos cuyos padres tenían una estatura muy superior al valor medio tendían a igualarse a éste, mientras que aquellos cuyos padres eran muy bajos tendían a reducir su diferencia respecto a la estatura media; es decir, "regresaban" al promedio.2 La constatación empírica de esta propiedad se vio reforzada más tarde con la justificación teórica de ese fenómeno.
El término lineal se emplea para distinguirlo del resto de técnicas de regresión, que emplean modelos basados en cualquier clase de función matemática. Los modelos lineales son una explicación simplificada de la realidad, mucho más ágil y con un soporte teórico por parte de la matemática y la estadística mucho más extenso.
Pero bien, como se ha dicho, podemos usar el término lineal para distinguir modelos basados en cualquier clase de aplicación.
[editar]
El modelo de regresión lineal
El modelo lineal relaciona la variable dependiente Y con K variables explicativas  (k = 1,...K), o cualquier transformación de éstas, que generan un hiperplano de parámetros
(k = 1,...K), o cualquier transformación de éstas, que generan un hiperplano de parámetros  desconocidos:
desconocidos:
(k = 1,...K), o cualquier transformación de éstas, que generan un hiperplano de parámetros desconocidos:(2)

donde  es la perturbación aleatoria que recoge todos aquellos factores de la realidad no controlables u observables y que por tanto se asocian con el azar, y es la que confiere al modelo su carácter estocástico. En el caso más sencillo, con una sola variable explicativa, el hiperplano es una recta:
es la perturbación aleatoria que recoge todos aquellos factores de la realidad no controlables u observables y que por tanto se asocian con el azar, y es la que confiere al modelo su carácter estocástico. En el caso más sencillo, con una sola variable explicativa, el hiperplano es una recta:
es la perturbación aleatoria que recoge todos aquellos factores de la realidad no controlables u observables y que por tanto se asocian con el azar, y es la que confiere al modelo su carácter estocástico. En el caso más sencillo, con una sola variable explicativa, el hiperplano es una recta:(3)

El problema de la regresión consiste en elegir unos valores determinados para los parámetros desconocidos , de modo que la ecuación quede completamente especificada. Para ello se necesita un conjunto de observaciones. En una observación cualquiera i-ésima (i= 1,... I) se registra el comportamiento simultáneo de la variable dependiente y las variables explicativas (las perturbaciones aleatorias se suponen no observables).
, de modo que la ecuación quede completamente especificada. Para ello se necesita un conjunto de observaciones. En una observación cualquiera i-ésima (i= 1,... I) se registra el comportamiento simultáneo de la variable dependiente y las variables explicativas (las perturbaciones aleatorias se suponen no observables).(4)

Los valores escogidos como estimadores de los parámetros,  , son los coeficientes de regresión, sin que se pueda garantizar que coinciden con parámetros reales del proceso generador. Por tanto, en
, son los coeficientes de regresión, sin que se pueda garantizar que coinciden con parámetros reales del proceso generador. Por tanto, en
, son los coeficientes de regresión, sin que se pueda garantizar que coinciden con parámetros reales del proceso generador. Por tanto, en(5)

Los valores  son por su parte estimaciones de la perturbación aleatoria o errores.
son por su parte estimaciones de la perturbación aleatoria o errores.
son por su parte estimaciones de la perturbación aleatoria o errores.
[editar]
Hipótesis modelo de regresión lineal clásico
1. Esperanza matemática nula.

Para cada valor de X la perturbación tomará distintos valores de forma aleatoria, pero no tomará sistemáticamente valores positivos o negativos, sino que se supone que tomará algunos valores mayores que cero y otros menores, de tal forma que su valor esperado sea cero.
2. Homocedasticidad
 para todo t
para todo t
Todos los términos de la perturbación tienen la misma varianza que es desconocida. La dispersión de cada  en torno a su valor esperado es siempre la misma.
en torno a su valor esperado es siempre la misma.
en torno a su valor esperado es siempre la misma.
3. Incorrelación.  para todo t,s con t distinto de s
para todo t,s con t distinto de s
para todo t,s con t distinto de s
Las covarianzas entre las distintas pertubaciones son nulas, lo que quiere decir que no están correlacionadas o autocorrelacionadas. Esto implica que el valor de la perturbación para cualquier observación muestral no viene influenciado por los valores de la perturbación correspondientes a otras observaciones muestrales.
4. Regresores no estocásticos.
5. No existen relaciones lineales exactas entre los regresores.
6.  Suponemos que no existen errores de especificación en el modelo ni errores de medida en las variables explicativas
Suponemos que no existen errores de especificación en el modelo ni errores de medida en las variables explicativas
Suponemos que no existen errores de especificación en el modelo ni errores de medida en las variables explicativas
7. Normalidad de las perturbaciones 
[editar]
Supuestos del modelo de regresión lineal
Para poder crear un modelo de regresión lineal, es necesario que se cumpla con los siguientes supuestos:3
- La relación entre las variables es lineal.
- Los errores en la medición de las variables explicativas son independientes entre sí.
- Los errores tienen varianza constante. (Homocedasticidad)
- Los errores tienen una esperanza matemática igual a cero (los errores de una misma magnitud y distinto signo son equiprobables).
- El error total es la suma de todos los errores.
[editar]
Tipos de modelos de regresión lineal
Existen diferentes tipos de regresión lineal que se clasifican de acuerdo a sus parámetros:
[editar]
Regresión lineal simple
Sólo se maneja una variable independiente, por lo que sólo cuenta con dos parámetros. Son de la forma:4
(6)

donde 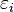 es el error asociado a la medición del valor
es el error asociado a la medición del valor 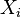 y siguen los supuestos de modo que
y siguen los supuestos de modo que  (media cero, varianza constante e igual a un
(media cero, varianza constante e igual a un  y
y  con
con 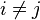 ).
).
es el error asociado a la medición del valor y siguen los supuestos de modo que (media cero, varianza constante e igual a un y con ).
[editar]
Análisis
Dado el modelo de regresión simple, si se calcula la esperanza (valor esperado) del valor Y, se obtiene:5
(7)

Derivando respecto a  y
y 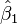 e igualando a cero, se obtiene:5
e igualando a cero, se obtiene:5
y e igualando a cero, se obtiene:5(9)

(10)
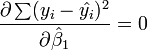
Obteniendo dos ecuaciones denominadas ecuaciones normales que generan la siguiente solución para ambos parámetros:4
(11)

(12)

La interpretación del parámetro  es que un incremento en Xi de una unidad, Yi incrementará en
es que un incremento en Xi de una unidad, Yi incrementará en
es que un incremento en Xi de una unidad, Yi incrementará en
[editar]
Regresión lineal múltiple
La regresion lineal nos permite trabajar con una variable a nivel de intervalo o razón, así también se puede comprender la relación de dos o más variables y nos permitirá relacionar mediante ecuaciones, una variable en relación a otras variables llamándose Regresión múltiple. Constantemente en la práctica de la investigación estadística, se encuentran variables que de alguna manera están relacionados entre si, por lo que es posible que una de las variables puedan relacionarse matemáticamente en función de otra u otras variables.
Maneja varias variables independientes. Cuenta con varios parámetros. Se expresan de la forma:6
(13)
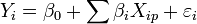
donde es el error asociado a la medición  del valor
del valor  y siguen los supuestos de modo que (media cero, varianza constante e igual a un y con ).
y siguen los supuestos de modo que (media cero, varianza constante e igual a un y con ).
es el error asociado a la medición del valor y siguen los supuestos de modo que (media cero, varianza constante e igual a un y con ).
[editar]
Rectas de regresión
Las rectas de regresión son las rectas que mejor se ajustan a la nube de puntos (o también llamado diagrama de dispersión) generada por una distribución binomial. Matemáticamente, son posibles dos rectas de máximo ajuste:7
- La recta de regresión de Y sobre X:
(14)

- La recta de regresión de X sobre Y:
(15)

La correlación ("r") de las rectas determinará la calidad del ajuste. Si r es cercano o igual a 1, el ajuste será bueno y las predicciones realizadas a partir del modelo obtenido serán muy fiables (el modelo obtenido resulta verdaderamente representativo); si r es cercano o igual a 0, se tratará de un ajuste malo en el que las predicciones que se realicen a partir del modelo obtenido no serán fiables (el modelo obtenido no resulta representativo de la realidad). Ambas rectas de regresión se intersecan en un punto llamado centro de gravedad de la distribución.
[editar]
Aplicaciones de la regresión lineal
[editar]
Líneas de tendencia
Véase también: Tendencia.
Una línea de tendencia representa una tendencia en una serie de datos obtenidos a través de un largo período. Este tipo de líneas puede decirnos si un conjunto de datos en particular (como por ejemplo, el PBI, el precio del petróleo o el valor de las acciones) han aumentado o decrementado en un determinado período.8 Se puede dibujar una línea de tendencia a simple vista fácilmente a partir de un grupo de puntos, pero su posición y pendiente se calcula de manera más precisa utilizando técnicas estadísticas como las regresiones lineales. Las líneas de tendencia son generalmente líneas rectas, aunque algunas variaciones utilizan polinomios de mayor grado dependiendo de la curvatura deseada en la línea.
[editar]
Medicina
En medicina, las primeras evidencias relacionando la mortalidad con el fumar tabaco9 vinieron de estudios que utilizaban la regresión lineal. Los investigadores incluyen una gran cantidad de variables en su análisis de regresión en un esfuerzo por eliminar factores que pudieran producir correlaciones espurias. En el caso del tabaquismo, los investigadores incluyeron el estado socio-económico para asegurarse que los efectos de mortalidad por tabaquismo no sean un efecto de su educación o posición económica. No obstante, es imposible incluir todas las variables posibles en un estudio de regresión.10 11 En el ejemplo del tabaquismo, un hipotético gen podría aumentar la mortalidad y aumentar la propensión a adquirir enfermedades relacionadas con el consumo de tabaco. Por esta razón, en la actualidad las pruebas controladas aleatorias son consideradas mucho más confiables que los análisis de regresión.
No hay comentarios:
Publicar un comentario